The 50-Year Convergence
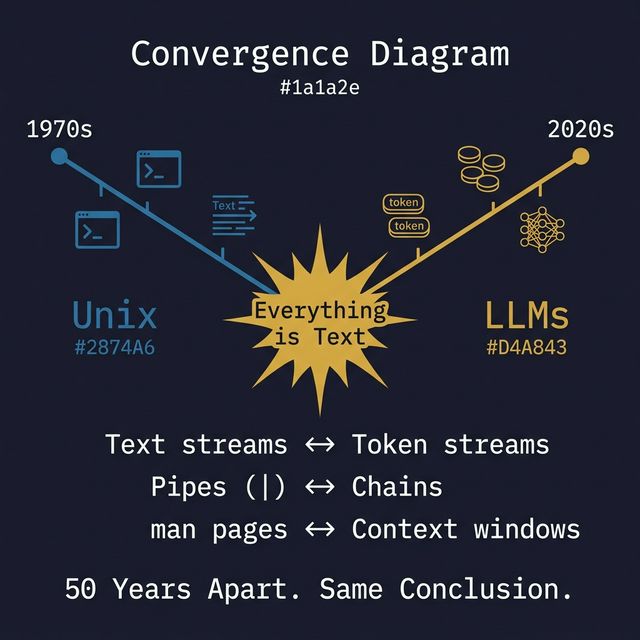
Unix decided everything is text in 1970. LLMs decided everything is tokens in 2020. Same conclusion.
The 50-Year Convergence
In 1970, Ken Thompson and Dennis Ritchie made a decision that would shape computing for half a century: everything is a text stream. Programs receive text. Programs produce text. Programs compose by piping text from one to the next. No binary formats required. No shared memory needed. Just text, flowing through pipes.
In 2020, a different group made almost the same decision: everything is tokens. Models receive text. Models produce text. Their thinking is text. Their actions are text. The feedback they receive from the world must be text.
Two systems. Fifty years apart. Same conclusion.
Familiar Ground
You use this convergence every day without naming it. When you open an AI coding session and the model runs a terminal command, reads the output, decides what to do next, and runs another command, you are watching a system that processes text interact with an environment that was designed for text processing.
The model did not need a special adapter. It did not need a proprietary protocol. It did not need a schema registry. The terminal was already speaking its language.
An engineer who spent two years building agents at one of the leading AI companies (later acquired by Meta) documented the discovery that surprised him: a single run(command="...") tool with Unix-style commands outperformed a catalogue of fifty typed function calls. Not by a small margin. Categorically.
Counter-Signal
The last two years of AI tooling went in the opposite direction. The industry built elaborate intermediary protocols: typed function schemas, structured tool definitions, standardised integration layers. Each tool needed its own description, parameter types, return format, and error handling specification.
This was reasonable in 2023, when models needed careful guidance. But models grew faster than the protocols did. By 2026, they write complex Python fluently. They navigate REST APIs from documentation alone. They use CLIs better than most junior developers.
The industry built a universal translator for systems that had already learned each other’s language.
Consider the cost. Every typed tool schema takes context window space. The model reads the tool description, the parameter types, the constraints, before it starts working. One estimate puts this at 15 to 20 percent of the context window consumed by integration overhead. You are paying for a translator your model no longer needs.
⚛️ The Fusion
Three ideas crash here, and the collision reveals something older than software architecture.
The text-stream homology is the structural core. Unix says: programs communicate through text. LLMs say: cognition operates on text. This is not metaphor. It is a precise structural parallel:
| Unix (1970s) | LLMs (2020s) |
|---|---|
| Text streams (stdin/stdout) | Token streams (input/output) |
Pipe composition (cmd1 | cmd2) | Chain composition (output of step 1 feeds step 2) |
Self-documenting (--help, man pages) | Context-readable (docs, README, API specs) |
| Exit codes (success/failure signal) | Structured responses (completion/error) |
| stderr (error channel) | Separate error reasoning |
| Small tools, each does one thing well | Atomic actions, each accomplishes one task |
When two systems separated by fifty years converge on the same interface model, you are not looking at a design trend. You are looking at a fundamental truth about composable computation: text is the universal substrate for systems that need to communicate without shared assumptions.
The training data argument explains why the convergence works so well in practice. LLMs have seen more shell commands in their training data than any individual developer has typed in a lifetime. GitHub repositories. Stack Overflow answers. Man pages. Shell tutorials. Documentation. The model is, functionally, the world’s most experienced terminal operator.
When you give a model a typed tool schema, you are teaching it a new language it has never seen. When you give it a terminal, you are handing it an interface it has practised billions of times. The training data alignment makes the convergence not just theoretically elegant but practically superior.
The “don’t invent, inherit” principle completes the collision. Unix already solved composability (pipes), discoverability (--help), error handling (exit codes, stderr), and workflow orchestration (shell scripts). It solved these in text, which is exactly the medium LLMs natively operate in. Building a new integration protocol means rebuilding what Unix proved, in a less battle-tested form, at a higher token cost.
What if you could see every integration layer you build as a translation layer between two systems that already speak the same language?
| Typed Tool Approach | Unix-Native Approach |
|---|---|
| 50+ tool definitions to maintain | 1 tool: run(command) |
| Schema consumes 15-20% of context | Near-zero integration overhead |
| Model learns new interface per tool | Model uses familiar interface (pre-trained) |
| Each tool: custom error handling | Unix standard: exit codes + stderr |
| Composition requires orchestration logic | Composition uses pipes: built into the OS |
| New interface for each capability | Same interface for every capability |
The New Pattern
The convergence thesis is diagnostic: when two independent systems separated by decades arrive at the same answer, the answer is probably structural, not accidental.
This diagnostic applies beyond the Unix-LLM case. Look for convergence across paradigms in your own domain. When two teams in different departments independently build similar solutions, that solution probably reflects the actual structure of the problem, not a design preference. When two industries adopt the same organisational pattern, the pattern probably reflects a fundamental constraint, not a fashion.
For agent architecture specifically, the implication is direct. Stop building translation layers between models and tools. The model already speaks the tool’s language. Give it a terminal, not a schema catalogue.
The practical test: take your most complex typed tool definition. Now write the equivalent as a shell command the model can run directly. If the shell version is shorter, faster, and more composable, your typed tool was a translation layer you did not need.
Three separate sources confirmed this on the same day: a practitioner proved that shell commands outperform typed schemas, a vendor shipped an agent loop built on shell execution, and an industry leader declared the typed integration protocol dead. Convergence at three altitudes, practitioner, vendor, industry, on the same day, on the same conclusion.
That is not a signal. That is a verdict.
The Open Question
Unix said everything is text. LLMs said everything is tokens.
Fifty years apart, two systems independently concluded that the universal interface is text flowing through composable transforms.
What other truth is hiding in the convergence between your oldest systems and your newest ones?
*This fusion emerged from a STEAL on the nix Agent thesis by a former Manus backend lead, captured alongside two convergent signals on the same day (14 March 2026).